Лекція 11. Дисперсія та її властивості
Дисперсія випадкової величини характеризує відхилення випадкової величини від її математичного сподівання.
Для характеристики цього відхилення неможливо використати його математичне сподівання, оскільки воно дорівнює нулю:
E(X-E(X))=E(X)-E(E(X))=E(X)-E(X)=0
Цей результат цілком природний. Він показує, що випадкова величина "однаково часто" відхиляється від свого математичного сподівання як у більшу, так і в меншу сторону. Щоб запобігти взаємному знищенню додатних і від'ємних значень відхилення X-E(X), можна замість самого відхилення розглядати його квадрат (X-E(X))2.
Означення. Дисперсією випадкової величини Х називається математичне сподівання квадрата відхилення цієї випадкової величини від її математичного сподівання, тобто
D(X)=E(X-E(X))2.
З властивостей математичного сподівання випливає, що дисперсію дискретної і нерерервної випадкових величин можна обчислити відповідно за формулами:

Використовуючи дисперсію для характеристики розсіювання випадкової величини, стикаємося з незручністю: якщо випадкова величина вимірюється в деяких одиницях, то дисперсія вимірюється у квадратах цих одиниць. Тому доцільно мати характеристику розсіювання значень випадкової величини тієї ж вимірності, що й сама величина. Такою характеристикою є середнє квадратичне відхилення. Означення. Середнім квадратичним відхиленням випадкової величини Х називається корінь квадратний із дисперсії D(X), тобто
![]()
Дисперсія має такі властивості
•Дисперсія будь-якої випадкової величини невід'ємна: D(X)≥0.
Доведення. Дисперсія – це математичне сподівання (середнє значення) невід'ємної випадкової величини D(X)=E(X-E(X))2.
•Дисперсія сталої величини дорівнює нулю, тобто якщо C=const, то D(C)=0.
•Сталий множник виноситься у квадраті за знак дисперсії, тобто якщо C=const, то D(CX)=C2D(X).
Доведення. D(CX)=E(CX)-E(CX))2=E(CX-CE(X))2=C2E(X-E(X))2=C2D(X).
•Дисперсія випадкової величини дорівнює різниці між математичним сподіванням квадрата цієї величини і квадратом її математичного сподівання, тобто D(X)=E(X)2)-(E(X))2.
Доведення.
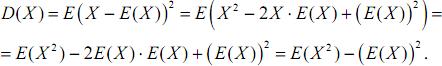
Дисперсія суми двох незалежних випадкових величин дорівнює сумі дисперсій цих величин, тобто D(X+Y)=D(X)+D(Y).
Доведення. Для незалежних випадкових величин Х і Y: E(XY)=E(X)·E(Y), тому
D(X+Y)=E(X+Y)2-(E(X+Y))2=E(X2)+2XY+Y2)-(E(X)+E(Y))2=E(X2)+2E(XY)+E(Y2)-E((X))2-2E(X)·E(Y)-(E(Y))2=E(X2)-E((X))2+E(Y2-E((Y))2=D(X)+D(Y).
•Дисперсія різниці двох незалежних випадкових величин дорівнює сумі дисперсій цих величин, тобто D(X-Y)=D(X)+D(Y).
•Якщо кожна з випадкових величин X1, X2,..., Xn не залежить від суми попередніх, то дисперсія суми цих величин дорівнює сумі їхніх дисперсій, тобто
D(X1+X2+...+Xn)=D(X1)+D(X2)+...+D(Xn).
Доведення. Досить застосувати метод математичної індукції і використати той факт, що дисперсія суми двох незалежних випадкових величин дорівнює сумі дисперсій цих величин.
Якщо випадкові величиниX1,X2,...,Xn– попарно незалежні, то дисперсія суми цих величин дорівнює сумі їхніх дисперсій:
D(X1+X2+...+Xn)=D(X1)+D(X2)+...+D(Xn).
Доведення. Досить повторити міркування, викладені у доведенні властивості D(X+Y)=D(X)+D(Y), замінивши у ньому формули квадрата суми двох доданків на формули квадрата суми n доданків.
Дисперсія випадкової величини, розподіленої за законом Пуассона. Для випадкової величини Х, розподіленої за законом Пуассона,
![]()
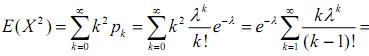
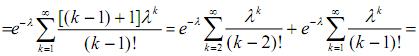
![]()
Отже,
![]()
тобто як і математичне сподівання, дисперсія випадкової величини Х, розподіленої за законом Пуассона, рівна параметрові цього розподілу λ .
Дисперсія рівномірно розподіленої випадкової величини. Для випадкової величини Х, рівномірно розподіленої на проміжку [a, b],
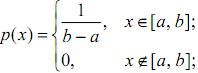
![]()
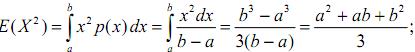
![]()
Дисперсія випадкової величини, розподіленої за біномним законом. Так розподілена кількість успіхів µ в п випробуваннях за схемою Бернуллі, якщо ймовірність успіху в одному випробуванні дорівнює р i q=1-p. Позначимо через µk кількість успіхів у випробуванні під номером k. Тоді µ=µ1+µ2+...+µn, E(µk)=p, µk2=µk, оскільки кількість успіхів в одному випробуванні може набувати лише значень 1 або 0. Отже,
![]()
![]()
Випадкові величини µ1,µ2,...,µn− попарно незалежні (бо випробування за схемою Бернуллі є незалежними), тому
![]()
Математичне сподівання та дисперсія нормально розподілної випадкової величини. Нагадаємо, що неперервна випадкова величина Х називається розподіленою за нормальним законом з параметрами -∞‹a‹+∞ і 0>σ якщо її щільність розподілу має вигляд:

Обчислимо математичне сподівання випадкової величини Х. Для цього в інтегралi

зробимо заміну 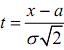 Тоді
Тоді ![]() і враховуючи, що
і враховуючи, що
![]()
одержимо:
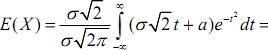

Дисперсію обчислимо за формулою:
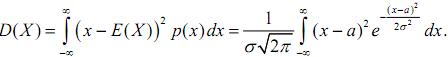
Знову зробимо заміну  , і отриманий інтеграл проінтегруємо частинами,
поклавши t=u 2te-t2=dv:
, і отриманий інтеграл проінтегруємо частинами,
поклавши t=u 2te-t2=dv:
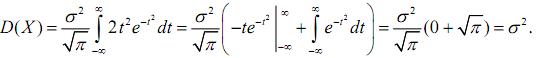
Отже, математичне сподівання і дисперсія нормально розподіленої випадкової величини відповідно дорівнюють a i σ2, тобто виражаються через параметри цього розподілу. Середнє квадратичне відхилення нормально розподіленої випадкової величини рівне параметрові σ цього розподілу:
![]()
Математичне сподівання двовимірної випадкової величин
Нехай задано п-вимірну випадкову величину (X1,X2,...,Xn). Її математичним сподіванням називається n-вимірний вектоp
(E(X1),E(X2),...,E(Xn)),
E(Xk)− математичне сподівання випадкової величини E(Xk).
Розглянемо, зокрема, двовимірну неперервну випадкову величину (X, Y) з щільністю розподілу ймовірностей p(x, y). Якщо px(x), py(y) − щільності розподілу випадкових величин Х і Y, то згідно з означенням математичного сподівання одновимірної випадкової величини

Однак,
![]()
тому
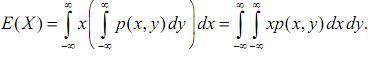
Аналогічно отримаємо формулу для E(Y):

Дисперсія двовимірної випадкової величини. Коваріація, коефіцієнт кореляції та його властивості
Означення. Дисперсією (або дисперсійною матрицею) n-вимірної випадкової величини (X1,X2,...,Xn) називається сукупність n2 чисел, які визначаються формулами
![]()
Очевидно, що дисперсійна матриця симетрична: bik=bki.
Для двовимірної випадкової величини (X ,Y) дисперсією є сукупність 3-х чисел: b11, b22 i b12=b21. Перші два числа є дисперсіями компонент цієї випадкової величини b11=E((X-E(X))(X-E(X)))=E(X-E(X))2=D(X), b22=E(Y-E(Y))2=D(Y), а третя називається коваріацією випадкових величин Х і Y:
cov(X, Y)=E((X-E(X))(Y-E(Y))),
або після розкриття дужок:
cov(X, Y)=E(XY)+E(X(-E(Y)))+E(-E(X)·Y)+E(E(X)E(Y))=E(XY)-E(XY)-E(X)E(Y)+E(X)E(Y)=E(XY)-E(X)E(Y).
З отриманої формули випливає, що коваріація незалежних випадкових величин дорівнює нулю.
Зв'язок між дисперсією та коваріацією встановлюють формули:
cov(X,X)=D(X); D(X+Y)=D(X)+2cov(X,Y)+D(Y).
Справді,
D(X+Y)=E((X+Y)-E(X+Y))2=E((X-E(X))+(Y-E(Y)))2=E(X-E(X))2+2E((X-E(X))(Y-E(Y))2=D(X)+2cov(X,Y)+D(Y).
Використовуючи означення математичного сподівання, одержимо:
•для дискретного розподілу
![]()
•для неперервного розподілу
![]()
Коваріація двох випадкових величин Х і Y характеризує не тільки ступінь взаємозалежності цих випадкових величин, а й також їхнє розсіювання навколо точки (E(X),E(Y)) на площині.
Розмірність коваріації cov(X, Y)дорівнює добуткові розмірностей випадкових величин Х і Y. Для того, щоб отримати безрозмірну величину, до того ж таку, яка характеризує тільки залежність між випадковими величинами, а не їхнє розсіювання, вводиться поняття коефіцієнта кореляції.
Означення. Коефіцієнтом кореляції між випадковими величинами Х і Y називається відношення коваріації до добутку середніх квадратичних відхилень цих величин:
![]()
Розглянемо властивості коефіцієнта кореляції.
•Коефіцієнт кореляції незалежних випадкових величин дорівнює нулю. Доведення. Для незалежних випадкових величин Х і Y cov(X, Y)=0.
• Для будь-яких випадкових величин |ρ(X,Y)|≤1.
Доведення. Досить довести, що ρ2(X,Y)≤1, тобто
cov2(X,Y)≤D(X)D(Y).
Оскільки математичне сподівання невід'ємної випадкової величини невід'ємне, то для кожного дійсного числа t маємo E(t(X-E(X))-(Y-E(Y)))2≥0, тобто
t2·D(X)-2t·cov(X,Y)+D(Y)≥0.
У лівій частині цієї нерівності – квадратний тричлен відносно t з додатним коефіцієнтом при t2. Цей тричлен буде невід'ємним для всіх дійсних значень t тоді і лише тоді, коли його дискримінант недодатний:
4cov2(X,Y)-4D(X)D(Y)≤0,
отже, виконується нерівність (1).
•|ρ(X,Y)|=1 тоді і лише тоді, коли випадкові величини зв'язані лінійною залежністю Y=αX+β. Тоді
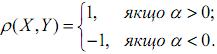
Доведення. (⇒) Нехай |ρ(X,Y)|=1, тобто cov2(X,Y)=D(X)D(Y), тому дискримінант квадратного тричлена у лівій частині нерівності (2) рівний нулю, і цей тричлен має двократний дійсний корінь
t=α=(cov(X,Y))/(D(X)).
Підставивши t=α у рівність E(t(X-E(X))-(Y-E(Y)))2=0, одержимо
E(αX-Y-E(αX-Y))2=0,
тобто D(αX-Y)=0. Це означає, що випадкова величина αX-Y є сталою, позначимо її через -β. Отже, αX-Y=-β, тому Y=αX+β. В (4) D(X)>0, тому числа α і cov(X,Y) мають однакові знаки. Але ж знак ρ(X,Y) визначається знаком cov(X,Y), а, отже, й знаком ,α тобто виконується (3).
(‹-) Нехай випадкові величини зв'язані лінійною залежністю Y=αX+β. Доведемо, що |ρ(X,Y)|=1, тобто cov2(X,Y)=D(X)D(Y).
Оскільки
E(Y)=E(αX+β)=αE(X)+β, Y-E(Y)=αX+β-αE(X)-β=α(X-E(X)),
то
cov(X,Y)=E((X-E(X))(Y-E(Y)))=E(α(X-E(X))2)=αD(X).
З другого боку, D(Y)=D(αX+β)=D(αX)+D(β)=α2D(X). Отже,
cov2(X,Y)=α2(D(X))2, D(X)D(Y)=D(X)·α2D(X)=α2(D(X))2,
тобто cov2(X,Y)=D(X)D(Y). Теорему доведено.
Модуль коефіцієнта кореляції випадкових величин Х і Y характеризує ступінь тісноти лінійної залежності між ними. Якщо лінійної залежності немає, то ρ(X,Y)=0. Якщо між випадковими величинами існує лінійна функціональна залежність Y=αX+β, то ρ(X,Y)=1 при α>0 і ρ(X,Y)=-1 при α‹0.
Означення. Дві випадкові величини Х і Y називаються корельованими, якщо ρ(X,Y)≠0 і некорельованими, якщо ρ(X,Y)=0.
Легко переконатися, що дві корельовані випадкові величини є також залежні (якщо припустимо від супротивного, що вони незалежні, то прийдемо до суперечності ρ(X,Y)=0). Обернене твердження правильне не завжди, тобто якщо дві випадкові величини залежні, то вони можуть бути як корельованими, так і некорельованими. Покажемо, зокрема, на прикладі, що може бути ρ(X,Y)=0) навіть для випадкових величин, зв'язаних функціональною залежністю, тобто з некорельованості випадкових величин не завжди випливає їхня незалежність.
Приклад.
Нехай випадкова величина Х рівномірно розподілена на проміжку [-1, 1], Y=X2. Тоді

![]()
Можна довести, що для нормально розподілених випадкових величин Х і Y некорельованість рівносильна незалежності.